HTML-to-PDF Performance Architecture: Native Byte Compilation vs. Headless Abstractions
When designing high-throughput microservices, it is easy to assume that small variations in static artifact deployment, like a slight difference in a Docker image size, represent minimal operational variance. However, raw disk footprint means absolutely nothing compared to runtime execution realities.
To quantify the cost of runtime abstractions, I designed an isolated, local multi-stage container suite benchmarking three structurally distinct patterns for an HTML-to-PDF conversion service:
1. Slim Jim (Native Approach): In-memory parsing and stream compilation to native PDF bytes using BeautifulSoup4 and ReportLab.
2. wkhtmltopdf (Legacy Wrapper): Inter-process pipeline execution wrapping an external WebKit binary via python-pdfkit.
3. Playwright (Browser Orchestration): Headless automated browser lifecycle management spinning up dedicated Chromium tab rendering cycles.
The Concurrency Workload
The target endpoints were exposed via a single-worker FastAPI instance hosted inside isolated Linux containers running on an active Docker Desktop engine. The load test simulates a high-concurrency event using the Go-based load generator hey:
- Total HTTP POST Requests: 1,000
- Concurrent Workers: 50 simultaneous callers
- Target Environment: Python 3.11-slim base images running on Debian Trixie
Core Benchmark Metrics
The Master Matrix
| Metric | Slim Jim (Native) | wkhtmltopdf (Wrapper) | Playwright (Browser) |
|---|---|---|---|
| Static Image Size | 314 MB | 267 MB | 1.51 GB |
| Cold Start Latency | ⚡ 29.59 ms | 🐢 309.33 ms | 🐢 202.86 ms |
| Peak RAM Utilization | 🔋 51.43 MiB | 🔋 60.47 MiB | 🚨 304.70 MiB |
| Total Workload Time | ⚡ 1.691 seconds | 🚨 214.609 seconds | 28.104 seconds |
| Throughput (Req/Sec) | 🚀 591.36 req/s | 📉 4.65 req/s | 35.58 req/s |
| Average Latency | ⚡ 66.9 ms | 3.49 seconds | 1.40 seconds |
| 99th Percentile Latency | ⚡ 735.5 ms | 17.36 seconds | 1.61 seconds |
| HTTP Success Rate | 100% (1000/1000) | 🚨 77.8% (778/1000) | 100% (1000/1000) |
🛠️ Reproducibility Note: You can inspect the implementation details or replicate the environment metrics locally via the Public GitHub Gist.
. . .
 Figure 1: Isolated container image definitions. While pdfkit enjoys a minor edge on disk space, Playwright introduces a massive 1.51 GB footprint due to embedded Chromium core layers.
Figure 1: Isolated container image definitions. While pdfkit enjoys a minor edge on disk space, Playwright introduces a massive 1.51 GB footprint due to embedded Chromium core layers.
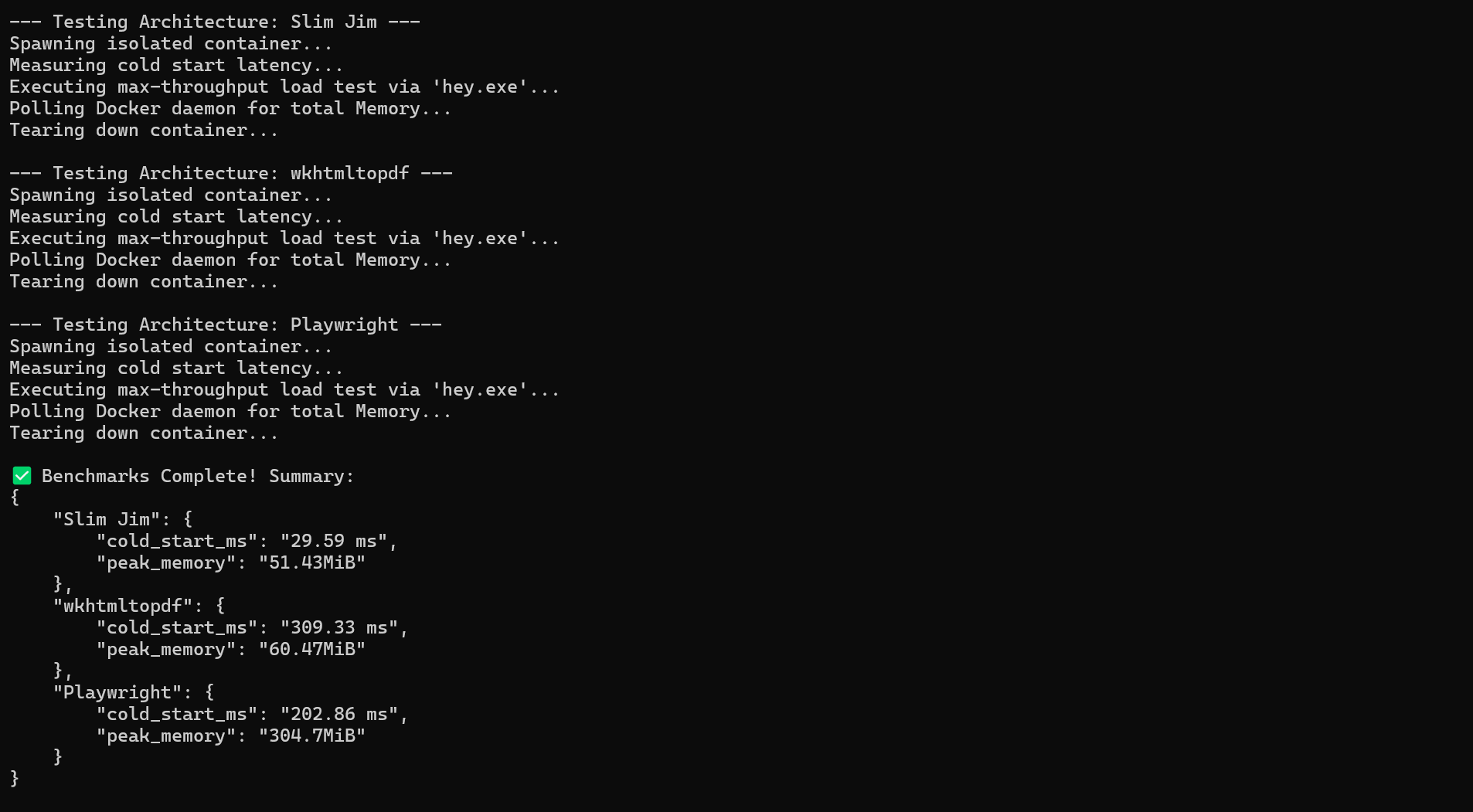 Figure 2: Raw runtime results showing the cold-start and peak memory capture across the isolated suite.
Figure 2: Raw runtime results showing the cold-start and peak memory capture across the isolated suite.
Architectural Deep Dive: Analyzing the Log Distributions
1. Slim Jim: Flat and Predictable Execution
Slim Jim achieved the ideal performance profile for high-volume backends: a completely flat execution distribution.
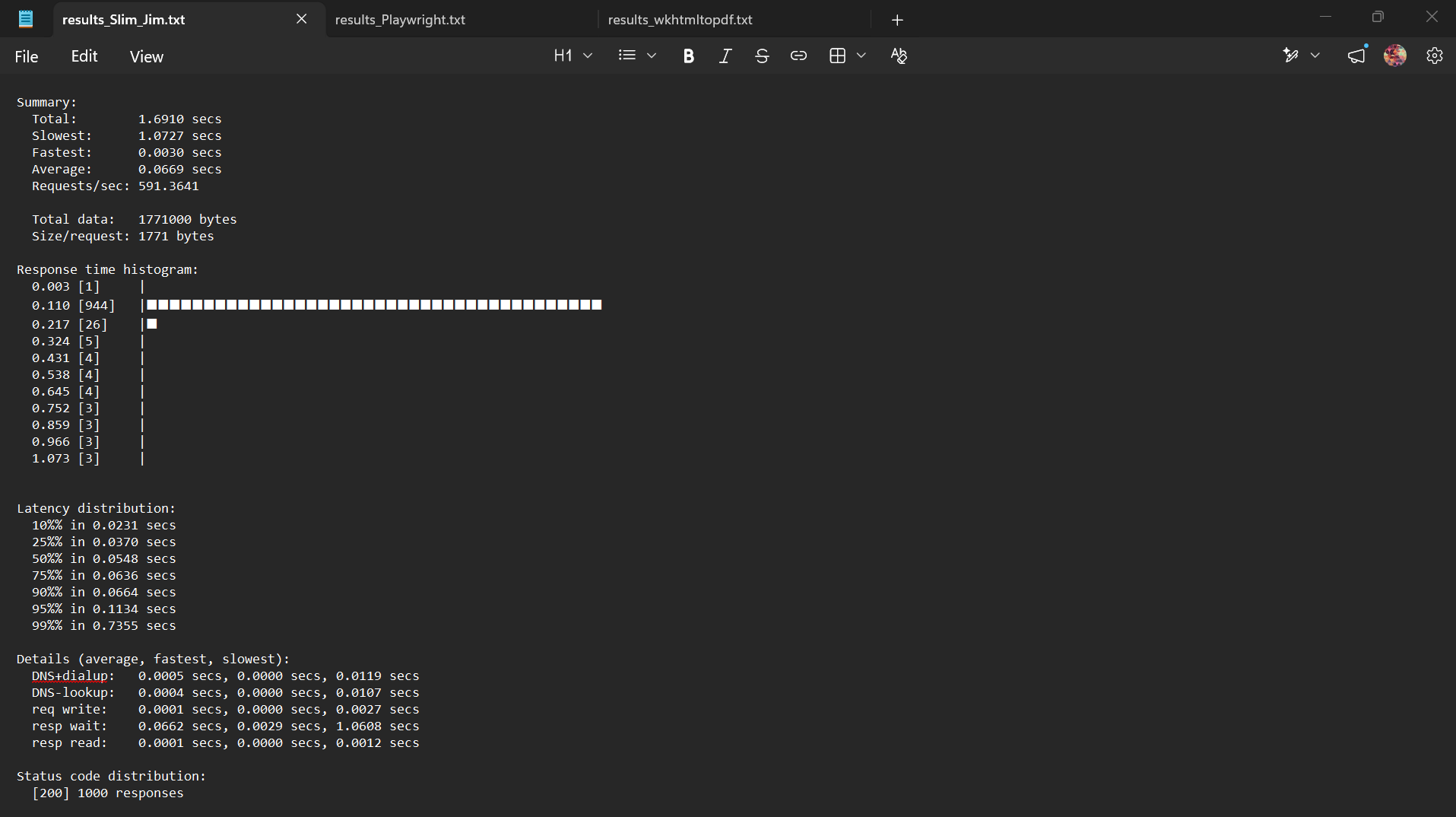 Figure 3: Slim Jim throughput analysis.
Figure 3: Slim Jim throughput analysis.
As seen in Figure 3, 94.4% of all requests (944 out of 1000) fell squarely into the lowest latency bucket between 3ms and 110ms. Because it parses tokens directly within pre-allocated Python memory structures and compiles native bytes directly onto a PDF canvas stream, it sidesteps operating system overhead entirely. The engine maintained an average response window of 66.9 ms while scaling up to 591.36 requests per second.
2. Playwright: The Heavy Browser Abstraction Tax
Playwright reliably completed the workload with a 100% success rate, but it penalized the infrastructure at an immense resource cost.
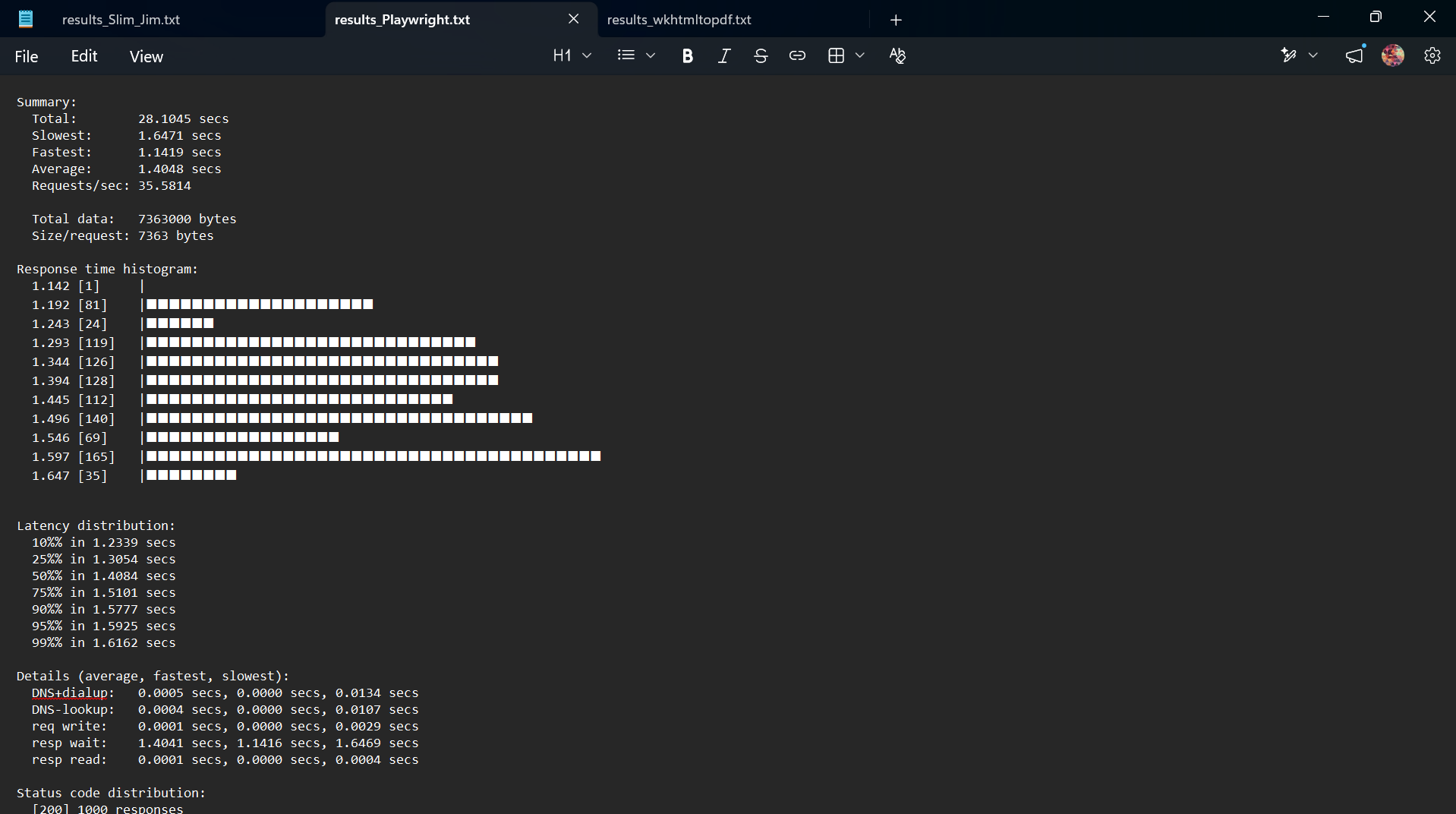 Figure 4: Playwright throughput analysis.
Figure 4: Playwright throughput analysis.
Because Playwright must initialize a headless Chromium rendering loop, create browser contexts, and manage automated tab instances, it encounters a hard latency ceiling. The fastest single request took 1.14 seconds. Under concurrency, this forced an average processing delay of 1.40 seconds across the entire distribution.
Furthermore, at 304.70 MiB of peak RAM, its operational memory footprint represents a 492% increase over Slim Jim, vastly multiplying computing costs in serverless architectures like AWS Lambda.
3. wkhtmltopdf: The Process-Forking Meltdown
The most significant failure occurred inside the wkhtmltopdf service wrapper, which collapsed completely under a 50-worker concurrency load.
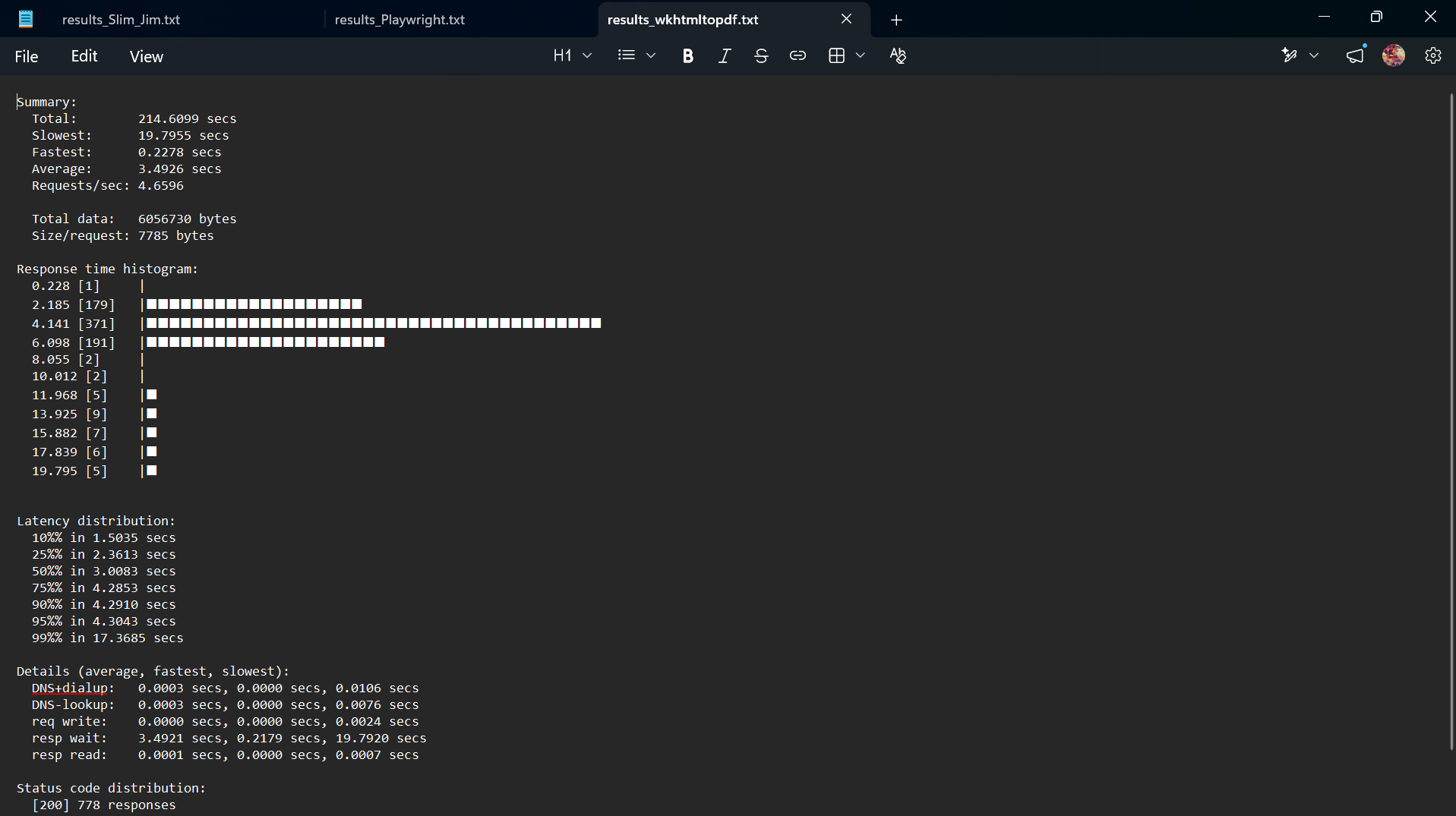 Figure 5: wkhtmltopdf throughput analysis.
Figure 5: wkhtmltopdf throughput analysis.
While wkhtmltopdf appeared highly efficient at rest (267 MB image size, 60.47 MiB peak RAM), its architecture relies on an explicit anti-pattern for concurrent backends: it forks the operating system kernel for every single incoming request via a subprocess pipe to /usr/local/bin/wkhtmltopdf.
Under a 50-worker surge, the host CPU became totally gridlocked by thread context-switching overhead. As visualized in the distribution histogram (Figure 5), response times thrashed outward violently, stretching the average processing cycle to 3.49 seconds and maxing out at a critical 19.79 seconds. This processing bottleneck completely exhausted the client request window, resulting in 221 requests failing outright due to context deadlines exceeding.
The System Design Takeaway
The choice between these patterns comes down to a definitive trade-off between layout flexibility and runtime scalability:
- Choose Heavy Abstractions (Playwright): When the application must render arbitrary third-party inputs relying on complex modern web layout specs like CSS Flexbox, CSS Grid, or runtime client-side JavaScript execution.
- Choose Specialized Byte Streaming (Slim Jim): When generating high-volume, data-dense internal documents (such as invoices, bills of lading, manifests, or shipping labels) using predictable structural templates.
By taking the time to design semantic templates compatible with a lightweight native bytecode compiler rather than leaning on a bulky browser environment, we unlock a 1,500%+ throughput advantage over Playwright, drop resource utilization by ~83%, and ensure absolute execution stability under high concurrency.